Patent Mining
January 22, 2018
Science has two competing
ideals. While
replication of experiments is important, you're not going to get ahead in your field by duplicating other people's work.
Scientific papers are expected to have a long list of
references, presumably the result of a thorough search of the topic area, lest you "
reinvent the wheel." Unintentional duplication of something that's already been done is wasteful of your time and your
funding agency's money.
Software development takes a lot of resources, so
code reuse and
free and open-source software (FOSS) are examples of using the wheels that have already been invented.
In the distant past, before the
Internet, doing original
research merely meant carefully scanning the one, or two,
topical journals in your
specialty, attending one or several
topical conferences each year, and maintaining contact with a small group of scientists who work in your niche area. I did all these when I was active in research on
magnetic materials. However, today, things are more difficult. There's a
plethora of online materials to scan, most of which are found, at best, to be not that relevant; or, at worst, completely wrong. There's also
Google, which gives way-too-many leads, and
commercial databases.
While every scientist wants to do research in exciting topic areas, "hot" research areas come and go. The first
decade of my tenure in
corporate research involved
magnetic bubble memory materials, a hot research area at that time. Attendance was huge at conferences at which magnetic bubble research was presented; but, alas,
semiconductor technology superseded any advantage that magnetic bubble memory offered, and I needed to migrate to other research areas. If I had learned anything from my
undergraduate economics course, there's a point at which
buggy whip manufacturers need to quit.

A magnetic bubble memory module.
This memory module, apparently date-coded for March, 1983, was manufactured by Intel, which believed at the time that magnetic bubble memory would be an important technology.
(Photo by the author, via Wikimedia Commons.)
In the past, when there was no Internet and all
books were collected in
libraries, you could get an idea of what scientific topics were popular at various times by counting books and
journal articles on those topics and graphing the numbers by date. Such insight into scientific and
cultural trends became much easier in 2011 with the introduction of a new
data mining tool from
Google Labs called the
Ngram Viewer.[1-2] The Ngram Viewer was developed over four years by a huge team of researchers from many departments at
Harvard University, and from
Harvard Medical School,
MIT,
Google, Inc.,
Houghton Mifflin Harcourt (the
American Heritage Dictionary people) and
Encyclopaedia Britannica, Inc..[1-2]
The Ngram Viewer team assembled a
corpus of about 4% of all books ever printed, and they developed software for easy analysis of this database. The Ngram Viewer is essentially a
concordance of a
random selection of 4% of every
published word, and the project has its own
website,
www.culturomics.org. Since this is a concordance, this database of 500 billion words collected from 5,195,769 books, is
copyright-free. It should be noted that the words are from books, only, since the dating of
periodicals in Google Books was very poor. The database extends to the year 2000, only.
I've written about the Ngram Viewer in a few previous articles:
• Culturomics, January 13, 2011
• Physics Top Fifty, July 19, 2011
• Word Extinction, August 17, 2011
• Modeling Scientific Citation, December 16, 2011
• Plotting Emotions, April 10, 2013
• As You Write, So You Are, August 21, 2013
The following
graph shows how useful the Ngram Viewer is in determining
historical trends in science. In this example I queried the Ngram viewer with typical terms from
chemistry (
phenol),
nuclear physics (
nuclear reaction), and
ubiquitous computing (
microprocessor). The graph seems to mark the domains of the chemical
age, the
nuclear age, and the
information age. Note that you need to be careful in your word selections. Just using
nuclear will give you
biology papers as well. The nuclear age doesn't appear all that important by this
analysis, but you would likely need to average many terms to get the true picture.
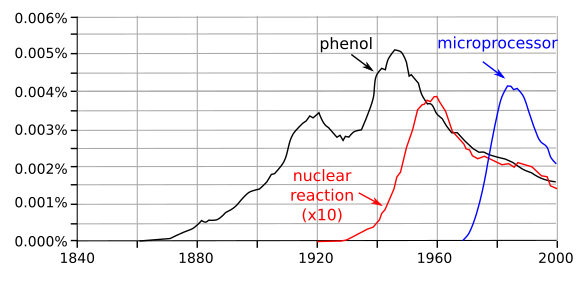
The chemical, nuclear, and information ages, as determined by the Ngram Viewer. While the database stops at the year 2000, it's likely that the next age will be the age of artificial intelligence. (Graphs from the Ngram viewer, redrawn for clarity using Inkscape. Click for larger image.)
While it's entertaining to see historical trends, most people, especially
entrepreneurs and
venture capitalists, are interested in
future trends.
Artificial intelligence (AI) has become more important, but what topics in AI, for example, are worth a
scientist's time and a venture capitalist's money? That's the problem addressed in a recent
arXiv paper by researchers at the
University of Electronic Science and Technology of China (Chengdu, PR China), the
University of Fribourg (Fribourg, Switzerland),
Bern University Hospital (Bern, Switzerland), the
University of Bern (Bern, Switzerland), and the
University of Oxford (Oxford, UK). Instead of an analysis of journal articles or books, this research team looked at
United States patents, specifically how they are
interconnected via
citations.[3]
The importance of a scientific paper is judged by its
citation impact; that is, how often it is cited in other papers.
Albert Einstein's papers
have been cited 111,939 times.[4] Einstein's most cited paper is his
thought experiment on
quantum mechanics, now called the
EPR Paradox, that he co-authored with
Boris Podolsky and
Nathan Rosen.[5] The EPR paper has been cited 16,150 times.[4] Patent documents also include citations to previous work, including previous patents, to provide evidence for the
novelty of the invention.
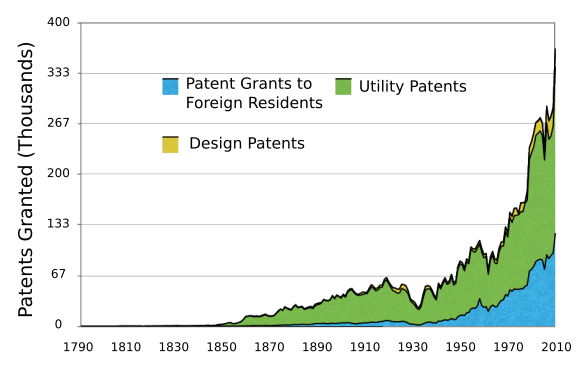
Do you see a trend? US patents granted each year from 1790-2008. (Wikimedia Commons image by Spitzl, modified for clarity using Inkscape)
As a cited
inventor on many patents in my corporate research career, I know from experience that few patents make enough money to even cover the cost of the patenting process, and fewer still describe world-changing technology. Just a small fraction of patents represent important technological advances.[3] The objective of this study was a
metric that allows for early identification of technologies, such as the
smartphone, that lead to radical
social changes. The trial metrics were tested using a list of historically significant patents.[3]
While it's known that, on average, important patents tend to receive more citations, the
correlation is
noisy and not that
predictive.[3] While
statistical analysis demands a large number of citations for best
estimates, accumulating citations takes time. Statistics might be fine in historical studies of the importance of older patents, but not that useful for detection of recent important patents.[3]
As they say, "You're known by the company you keep," and that's the idea behind the
PageRank concept used by
Google in
Internet search.[5] In the patent context, the idea is that important patents will be cited by other important patents.[3] It's found that highly-cited patents tend to cite other highly-cited patents, but one problem with both PageRank and simple citation counting is that they are
biased towards old patents, and we're really interested in recent patents.[3] To remedy this, the research team used an "age-rescaling" approach that removes the age bias for simple citation counting and simple PageRank (see graph).[3]
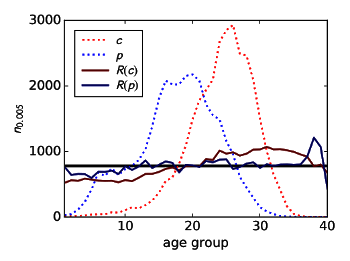
Removal of age bias of algorithms for discovery of recent important patents.
Legend: Citation count (c), PageRank score (p), age-rescaled citation count R(c), and age-rescaled PageRank R(p).
(Fig. 2 of Ref. 3, via arXiv)
This study suggests that important patents build on other other important patents, the typical "
standing on the shoulders of giants" effect.[3] There is some noise in the system caused by the fact that
patent examiners add their own citations.[3]
References:
- Jean-Baptiste Michel, Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres, Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak, and Erez Lieberman Aiden, "Quantitative Analysis of Culture Using Millions of Digitized Books," Science vol. 331, no. 6014 (January 14, 2011), pp. 176-182.
- Steve Bradt, "Oh, the humanity - Harvard, Google researchers use digitized books as a 'cultural genome'," Harvard University News Release, December 16, 2010.
- Manuel Sebastian Mariani, Matus Medo, and François Lafond, "Early identification of important patents through network centrality," arXiv, October 25, 2017.
- Google Scholar, "Albert Einstein - Institute of Advanced Studies, Princeton". It's interesting to note that Einstein has "no verified email."
- A. Einstein, B. Podolsky, and N. Rosen, "Can Quantum-Mechanical Description of Physical Reality Be Considered Complete?" Phys. Rev., vol. 47, no. 10 (May 15, 1935), pp. 777ff.,DOI:https://doi.org/10.1103/PhysRev.47.777.
- Lawrence Page, "Method for node ranking in a linked database," U.S. Patent No. 6,285,999, September 4, 2001.
Linked Keywords: Science; ideal; reproducibility; replication of experiments<; scientific paper; citation; reference; reinventing the wheel; funding of science; funding agency; software development; code reuse; free and open-source software; Internet; research; scientific journal; topical journals; specialty; academic conference; topical conference; magnetic material; plethora; Google; commerce; commercial; database; decade; corporate research; magnetic bubble memory; semiconductor device fabrication; semiconductor technology; undergraduate education; economics; course; buggy whip; Intel; technology; Wikimedia Commons; book; library; culture; cultural; data mining; Google Labs; Ngram Viewer; Harvard University; Harvard Medical School; Massachusetts Institute of Technology; MIT; Google, Inc.; Houghton Mifflin Harcourt; American Heritage Dictionary; Encyclopaedia Britannica, Inc.; corpus; concordance; randomness; random; publishing; published; word; website; www.culturomics.org<; copyright; periodical; Cartesian coordinate system; graph; history; historical; chemistry; phenol; nuclear physics; nuclear reaction; ubiquitous computing; microprocessor; periodization; age; nuclear age; information age; biology; analysis; chemical; nuclear; information; database; artificial intelligence; Inkscape; entrepreneurship; entrepreneur; venture capital; venture capitalist; forecasting; future trend; scientist; arXiv; University of Electronic Science and Technology of China (Chengdu, PR China); University of Fribourg (Fribourg, Switzerland); Bern University Hospital (Bern, Switzerland); University of Bern (Bern, Switzerland); University of Oxford (Oxford, UK); United States; patent; citation analysis; citation; citation impact; Albert Einstein; thought experiment; quantum mechanics; EPR Paradox; Boris Podolsky; Nathan Rosen; novelty; trend estimation; trend; Spitzl; invention; inventor; performance metric; smartphone; social change; correlation; statistical noise; noisy; prediction; predictive; statistical analysis; approximation; estimate; PageRank; Internet search; bias; algorithm; patent; standing on the shoulders of giants; patent examiner; Lawrence Page, "Method for node ranking in a linked database," U.S. Patent No. 6,285,999, September 4, 2001.