Scene Recognition
May 28, 2015
Most people are now aware that
object recognition by computer is now quite easy. The most common object recognition is
facial recognition, much beloved by the
surveillance state. Facial recognition is also being used by
social networking sites, who seek to "enhance" their user experience while enhancing their
advertising revenue.
While computer object recognition is generally able to pinpoint
knives in
X-ray images of
carry-on luggage for
airport security, differentiation between a
photograph of an
airport security area and a photograph of a busy
appliance store is generally difficult.
Scene recognition is a more difficult task than object detection, principally because scenes are composed of a variety of objects more appropriate to one scene than another.
A
home living room has many things in common with a
dentist's waiting room, such as
chairs,
walls covered with
artwork, a
television, and so forth. What are the distinguishing characteristics of a dentist's waiting room? I described this problem in terms of defining a chair in a
previous article (The Quality of Chairness, December 3, 2010).
What is the
quality of
chairness; that is, what makes a
chair, a
chair? Some chairs have four legs,
stools have three, and there are even one-legged chairs. A
desk becomes a chair when you sit on it. Does the desk forsake its quality of
deskness when that happens, or was it always both a desk and a chair?

This camping chair folds into a sack for storage. Is it still a chair when it's a sack? (Images by Jorge Barrios, via Wikimedia Commons.)
Computer scientists at the
Massachusetts Institute of Technology and
colleagues from
Princeton University and the
Universitat Oberta de Catalunya have been exploring scene identification.[1-4] Surprisingly, they've resurrected the
venerable artificial intelligence technique of
deep learning in
artificial neural networks. Using a compilation of seven million labeled scenes, they trained a neural network classifier to guess the scene type with greater
accuracy than previous attempts.[1]
Their first results were presented at the
Twenty-eighth Annual Conference on Neural Information Processing Systems (NIPS), December 7-13, 2014,[2] and most recently at the
2015 International Conference on Learning Representations (ICLR), May 7-9, 2015.[3] The authors of this research are
Bolei Zhou
Aude Oliva, and
Antonio Torralba of MIT,
Jianxiong Xiao of Princeton University, and
Agata Lapedriza of the Universitat Oberta de Catalunya, presently visiting at MIT.[1-3]
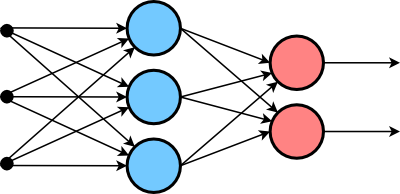
A two-layer artificial neural network. The input states are at the left, and the connections (arrows) are differently weighted.
(Via Wikimedia Commons.)
In their latest
paper, they show that, en route to scene recognition, their system learned how to recognize objects, so both processes can work in tandem; and, they can, in fact, be mutually reinforcing.[1] Essentially, you know you're in a
kitchen if you see both a
toaster and a
blender. Says MIT
associate professor of
computer science and engineering, Antonio Torralba,
"It could be that the representations for scenes are parts of scenes that don't make any sense, like corners or pieces of objects. But it could be that it's objects: To know that something is a bedroom, you need to see the bed; to know that something is a conference room, you need to see a table and chairs. That's what we found, that the network is really finding these objects."[1]
The object of neural network processing is to identify features in a
dataset as well as a
human would, but a neural network is not hardwired to identify specific features; rather, it establishes connections based on training data for specific categories. While humans are about 80% accurate at the scene identification task, the neural network eventually achieved 50% accuracy.[1] To determine the commonalities of each category, the research team identified the 60 images that produced the strongest response and sent the collections of images to
Amazon's Mechanical Turk, where
crowdsourced paid workers made the identification.[1]
It was found that the first layer of the multi-layer neural network was responding to simple
geometrical and
color clues. Says Torralba,
"The first layer, more than half of the units are tuned to simple elements — lines, or simple colors... As you move up in the network, you start finding more and more objects. And there are other things, like regions or surfaces, that could be things like grass or clothes. So they're still highly semantic, and you also see an increase."[1]

The first two layers of the MIT neural network appear to be tuned to geometrical patterns of increasing complexity, while the later layers focus on specific classes of objects. (MIT image. Click for larger image.)
Says Alexei Efros, an associate professor of
computer science at the
University of California, Berkeley,
"Our visual world is much richer than the number of words that we have to describe it... One of the problems with object recognition and object detection — in my view, at least — is that you only recognize the things that you have words for. But there are a lot of things that are very much visual, but maybe there aren't easy describable words for them. Here, the most exciting thing for me would be that, by training on things that we do have labels for — kitchens, bathrooms, shops, whatever — we can still get at some of these visual elements and visual concepts that we wouldn't even be able to train for, because we can't name them.”[1]
So, how well does the MIT neural network perform? Using their
Internet application,[4] I did tests using some of my own images. The first, an image of a
brook as shown below, was placed into the following semantic categories with assigned
probabilities -
swamp: 0.28,
rainforest: 0.15,
creek: 0.11, and
forest path: 0.08. The scene attributes were found to be
naturallight,
nohorizon,
vegetation,
foliage,
leaves,
trees,
natural,
openarea,
shrubbery, and
moistdamp. Having more
water in the brook would likely have shifted the identification from swamp to creek.

The left image shows the informative region for the category, "swamp," of the brook image at the right.
(Left image by the author; right image via the MIT Scene Recognition Demo).[4)]
The next image, a
fence in a
grassy area, gave the results noted below.

The MIT algorithm placed the left image in the following categories - yard: 0.25, pasture: 0.22, field/cultivated: 0.11, cemetery: 0.09, and vegetable garden: 0.06, based on the derived scene attributes of grass, nohorizon, naturallight, vegetation, openarea, man-made, camping, farming, foliage, leaves. The right image is the informative region for the category "yard." (Left image by the author; right image via the MIT Scene Recognition Demo).[4)]
References:
- Larry Hardesty, "Object recognition for free," MIT Press Release,May 8, 2015.
- Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio Torralba, and Aude Oliva, "Learning Deep Features for Scene Recognition using Places Database," Paper presented at the Twenty-eighth Annual Conference on Neural Information Processing Systems (NIPS), December 7-13, 2014 (PDF file).
- Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba, "Object Detectors Emerge In Deep Scene CNNs," Paper presented at the 2015 International Conference on Learning Representations (ICLR), May 7-9, 2015.
- MIT Scene Recognition Demo. As the instructions state, "Input a picture of an environment, a place, a scene, and check out how our model predicts it!"
Permanent Link to this article
Linked Keywords:
Object recognition by computer; facial recognition; surveillance state; social networking service; website; advertising; revenue; knife; knives; radiography; X-ray image; hand luggage; carry-on luggage; airport security; photography; photograph; airport security; major appliance; retail; store; scene; home; living room; dentist; waiting room; chair; wall; work of art; artwork; television set; quality; philosophy; stool; desk; camping; sack; Wikimedia Commons; Computer scientist; Massachusetts Institute of Technology; colleague; Princeton University; Universitat Oberta de Catalunya; venerable; artificial intelligence; deep learning; artificial neural network; accuracy; Twenty-eighth Annual Conference on Neural Information Processing Systems (NIPS); 2015 International Conference on Learning Representations (ICLR); Bolei Zhou; Aude Oliva; Antonio Torralba; Jianxiong Xiao; Agata Lapedriza; academic publishing; paper; kitchen; toaster; blender; associate professor; computer science and engineering; bedroom; bed; conference hall; conference room; table; dataset; human; Amazon's Mechanical Turk; crowdsourcing; crowdsourced; employer-worker relationship; paid worker; geometry; geometrical; color; line; surface; grass; clothing; clothes; semantics; semantic; Alexei Efros; computer science; University of California, Berkeley; visual perception; visual world; word; bathroom; shop; Internet application; brook; probability; probabilities; swamp; rainforest; stream; creek; forest; footpath; path; sunlight; natural light; no horizon; vegetation; foliage; leaf; leaves; tree; nature; natural; open space; shrubbery; moisture; moist; damp; water; MIT Scene Recognition Demo; fence; grass; grassy; yard; pasture; tillage; field; cultivated; cemetery; vegetable garden; artificial; man-made; camping; farm; farming.