What's in a Name?
April 11, 2011
How could I write an article with such a title without
quoting Shakespeare.[1]
"What's in a name? that which we call a rose
By any other name would smell as sweet..."
Words are built from
alphabet characters, and some characters are
more common in words than others. This works to the advantage of
cryptologists, who use this principle to
decipher weak
codes. There are available on the internet
frequency tables of character occurrence in many languages.[2] These depend, somewhat, on what
corpus has been analyzed, so there are minor differences between different tables for the same language.
It will come as no surprise that the letter
e is the most common character of the
English language (12.7%), followed by
t (9.056%),
a (8.167%) and
o (7.507%). The twelve most frequent characters, which are less than half the English alphabet, are used about 80% of the time. It's almost as if we can throw half our alphabet away, and still be understood.[3]
Everyone likes to think that their name is unique, and there may be some validity to that idea, as I'll explain. There's been some recent excitement about a discovery at
Fermilab that may indicate a new
subatomic particle, or possibly, a new type of force.[4] These results are interesting, since the data indicating such a finding are observed at the
three-sigma level. Most physicists start to believe in things at the two-sigma level, or about 95%
confidence. Three-sigma corresponds to a 99.7% confidence level, which looks like a near certainty.
As exciting as all this might be, we'll wait for more data from the
Large Hadron Collider before writing an article on this. The reason I mention this work is because the
preprint describing the Fermilab result posted on
arXiv has 507 authors.[5] This number is not unusual for a paper describing an
accelerator experiment, but it does give a convenient source of scientist names for analysis. As the figure shows, the frequency distribution of letters in these names shows significant differences from standard English text.
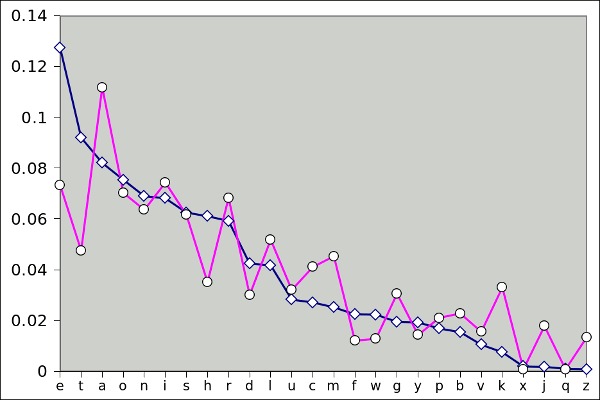
English letter distribution for general text (blue) and for the names of accelerator physicists (red). All characters of the listed name, including initials, were used, and non-English accented characters (e.g., á and é) were converted to non-accented characters. (Plot via Gnumeric)
As can be seen in the figure, the names of accelerator physicists are deficient in
e,
t and
h, and somewhat enriched in
a,
m and
k. Of special interest are
j and
z, which are nearly absent from general texts, but quite prevalent in these names.
I decided to develop a metric, which I call the Fermi Number, that expresses the "Ferminess" of a name; that is, with how much certainty we can put it in the same bin as the Fermilab authors. This equation, which doesn't use the actual
Fermi function, is as follows:

where f
fermilab is the frequency of a character in the Fermilab sample, f
general is the frequency of the same character in general text, and the sum is over all the characters
n in the word. Negative Fermi Numbers indicate that a name is not likely to be an author's name on a Fermilab paper, and positive numbers indicate that it might. As anecdotal evidence, my own last name has a Fermi Number of nearly zero (0.074074), and I'm not an
accelerator physicist.[6]
I'm supposedly a
materials scientist, so I looked at the Fermi Numbers of 347 authors of recently posted materials science articles on the arXiv preprint server; and also the Fermi Numbers of the
members of the US House of Representatives.
Histograms of these numbers appear in the following figure.
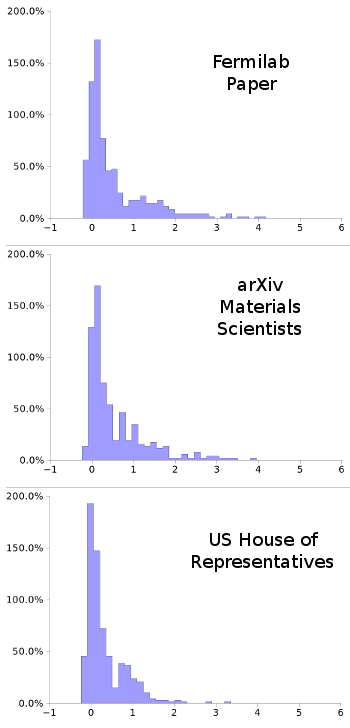
Histograms of Fermi Number occurrence in three populations.
1) The cited Fermilab paper.
2) Authors of materials science papers on the arXiv preprint server.
3) Members of the current US House of Representatives.
The Fermi Number average of each population is 0.509, 0.530 and 0.320, respectively.
Histogram plots via Gnumeric
From this very small sampling, it appears that names of scientists, whether they work with accelerators or
aluminum, follow the same distribution. The Fermi Number averages of these two populations are 0.509 and 0.530, respectively. This is quite different from that of the population of (mostly)
lawyers,[7] who have fewer large Fermi Numbers in the tail. This group has an average Fermi Number of just 0.320, indicative of a considerably reduced quality of "ferminess."
The Fermi Number analysis shows that the lawyerly population is quite different from the
scientific population. Could this explain why government funding of science is so low? This is definitely not a three sigma theory at this point, but if this analysis is done with much larger samples, it would be interesting to see the results.
References:
- William Shakespeare, "The Tragedy of Romeo and Juliet," via Wikisource.
- Letter Frequency page on Wikipedia.
- Devlin M. Gualtieri, "FauxCrypt - A Method of Text Obfuscation," arXiv Preprint Server, April 28, 2010.
- Thomas H. Maugh II, "Research points to a fundamental change in physics -- or else a fluke," Los Angeles Times, April 7, 2011.
- CDF Collaboration, T. Aaltonen, et al., "Invariant Mass Distribution of Jet Pairs Produced in Association with a W boson in ppbar Collisions at sqrt(s) = 1.96 TeV," arXiv Preprint Server, April 4, 2011.
- My analysis program, written in C, can be found here. The weights for alphabetic characters, a-z, can be found in this source code.
- Having started this article with a Shakespeare quotation, how can I resist mentioning his popular quotation, "The first thing we do, let's kill all the lawyers." (William Shakespeare, Henry the Sixth, Part II, IV, ii (1623)). Of course, I don't advocate violence of any sort against any group, so this is just an academic reference.
Permanent Link to this article
Linked Keywords: Shakespeare; alphabet; letter frequency; cryptography; cryptologists; cryptanalysis; decipher; codes; frequency tables; corpus; corpora; English language; Fermilab; subatomic particle; normal distribution; three-sigma; confidence interval; Large Hadron Collider; preprint; arXiv; synchrotron"; accelerator; Fermi function; accelerator physicist; materials scientist; US House of Representatives; histogram; Gnumeric; aluminum; lawyer; scientific; The Tragedy of Romeo and Juliet; FauxCrypt - A Method of Text Obfuscation.